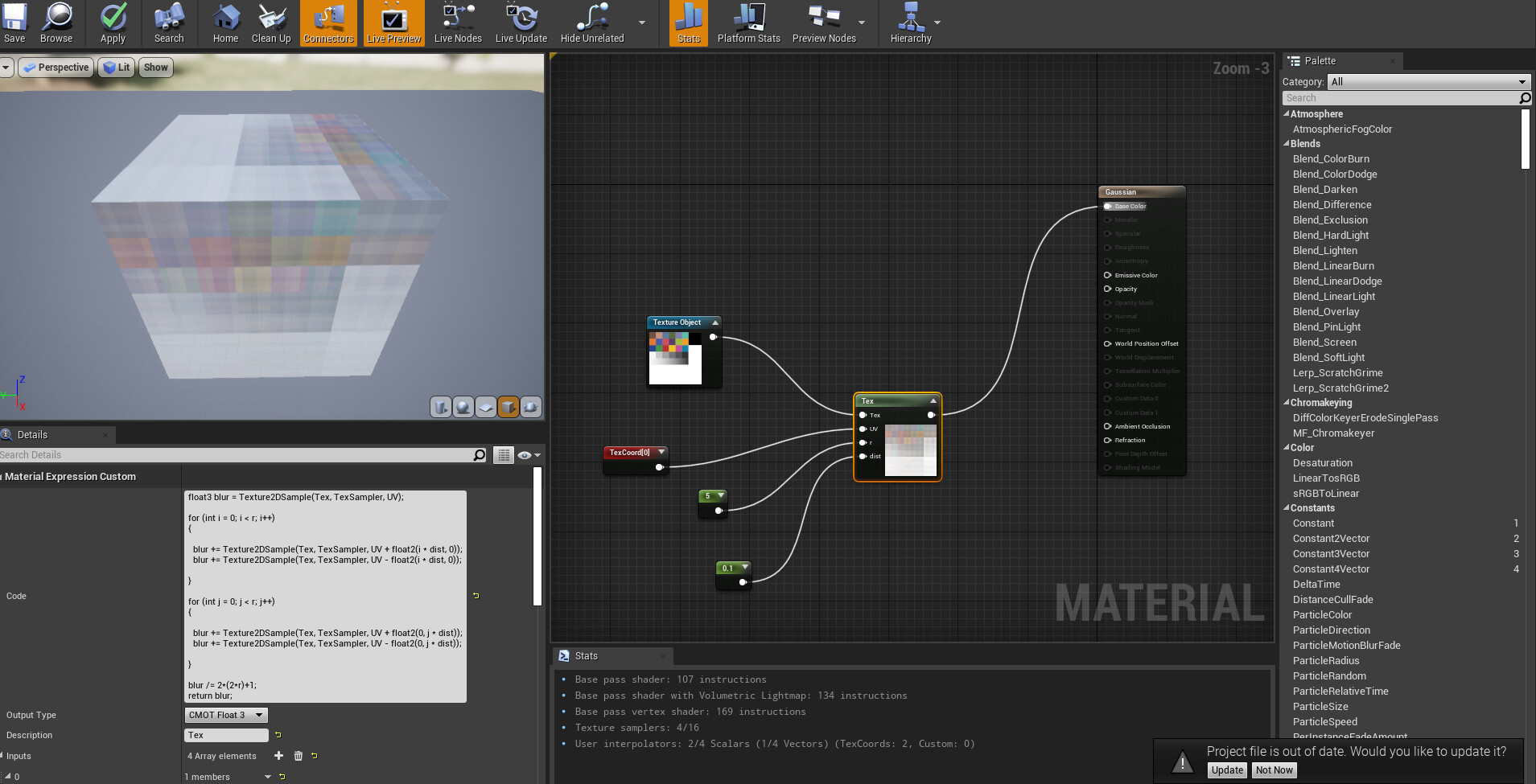
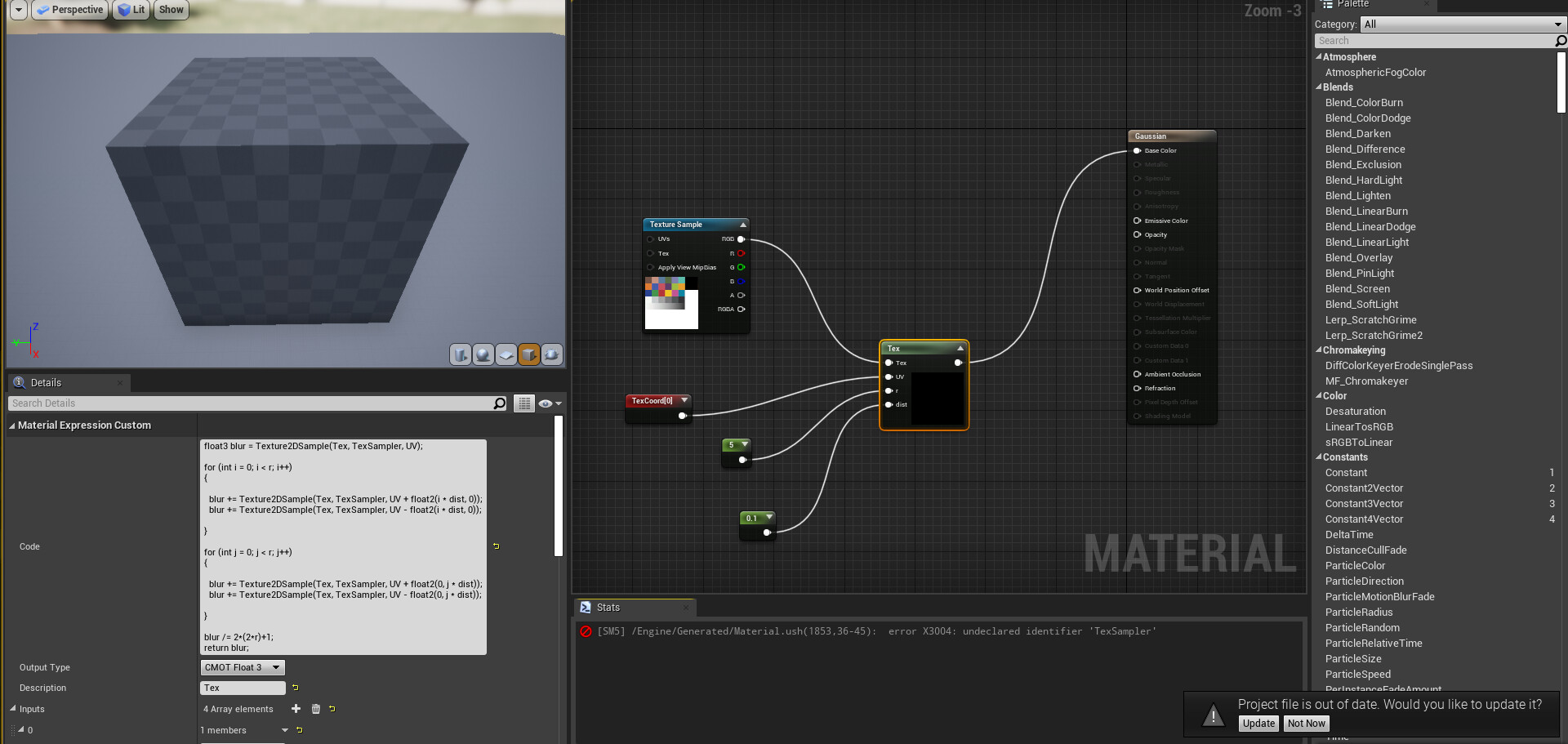
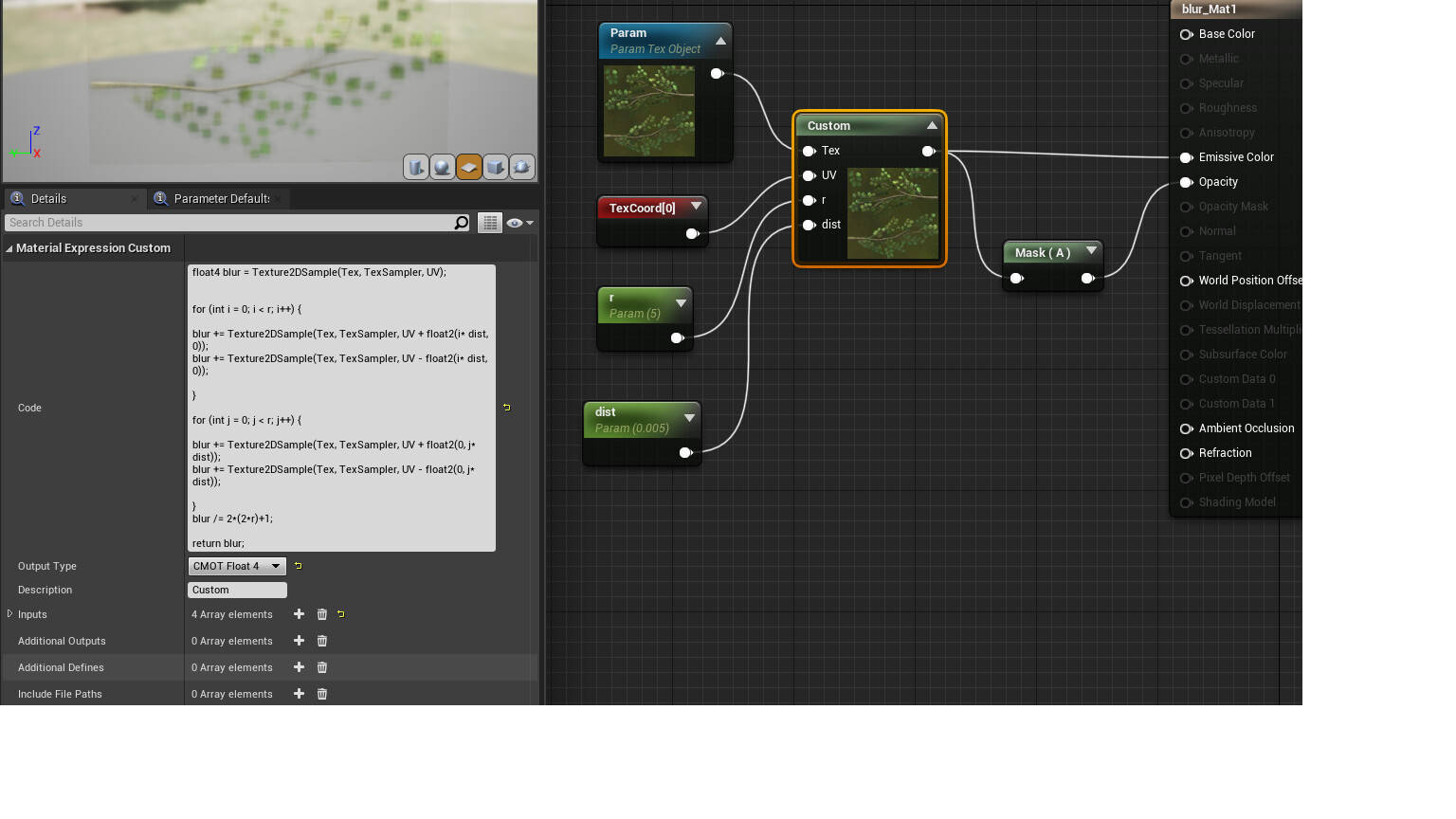
Well. The instruction count printed by unreal is not correct[0], for what that snipped of code is actually doing. Unreal’s pipeline is built around the nodegraph, not code nodes. The nodegraph doesn’t have proper flow control, so it’s not designed to evaluate instruction costs for loops(flow) - indeed it can’t if the iteration is dynamic. So, if you put a loop in there, it will ignore it and just count what’s in it once.
You are sampling a texture (r * 2) ^ 2 + 1 times so an r of 5 is 100 + 1. An r of 10 is 400 + 1 etc. Texture samples are much more expensive than single instructions, so to get an actual idea of what this would cost you would have to plop out 401 texture sampler nodes - and already there it’s obvious that what you are doing ain’t cheap. You also do (r * 6) ^ 2 additions, (r * 2) ^ 2 subtractions and (r * 4) ^ 2 multiplications, ignoring here the final bit outside the loop. Each of those additions, subtractions and multiplications counts as an instruction[1].
If you hardcode the r as a const int in the code and put an [unroll] before each of those loops, Unreal may actually show you the real instruction count, emphasis on the may.
Either way, what you have is a brute force blur. It’s a box blur actually, not a gaussian blur, since you’re not calculating a gaussian weight per sample. Normally if you do a thing like this you would do it in two passes. First blur x axis r steps save that to a texture, and then do y axis r steps of that texture. This is how bloom is often doing it. That would change the cost from ^ 2 to * 2. I don’t know if that can be done in the context of what you’re doing though.
All that said. If you have mipmaps generated for the texture, you can use those. Mips are naturally blurred and cheaper to sample[2]. You might be able to just sample maybe 4-5 mip biases down from the highest and sum those to get more or less the same thing for a fraction of the cost.
Here’s a rough untested example of a lot more more performant solution.
float r = 5;//(replace this with an input)
float blur = 2;//(replace this with an input)
float4 sum = 0;
for(int i = 0; i < r; i++)
{
sum += tex.SampleBias(View.MaterialTextureBilinearClampedSampler, UV, i * blur);
}
return sum / r;
You wrote you’re new to HLSL and shaders. Shaders are fun, have fun! But, I would always recommend trying to understand the code snippets you’re trying out and the implications. Best way to learn is to try things out, if you notice clear performance drops when you test is taking up the whole screen, you are doing too much work in the shader[3]. The more you understand it the better you can learn to evaluate if there is better alternative or smarter tricks to get to what you want. Compilers are usually real smart and can optimize a lot of things away - but they can’t replace whole methods for more performant ones.
The online directX HLSL intrinsic function manual is really informative too.
Here it’s explaining SampleBias SampleBias (DirectX HLSL Texture Object) - Win32 apps | Microsoft Docs
[0]: An empty default material is 116 instructions - you’re not blurring for just 4, I can guarantee you that :o)
[1]: A compiler will remove some of the duplicates, like (r * 4) ^ 2 probably becomes r ^ 2 since the result is the same for all 4 cases - it’s still a large number if r is high.
[2]: Mips are smaller, so it’s smaller blocks of memory for the sampler to handle - another source of performance issues: “oversampling”. Tile a texture on a huge plane forcing it to always sample mip 0 and even a high end graphics card may stall significantly, when several full res tiles cover just a few pixels on the horizon.
[3]: “stat unit” console command will show you the ms timers, if the gpu ms timer goes up by a lot compared to looking at a grey box, you are doing something expensive. This is by far the best indicator of a specific shader being expensive, without actually digging deeper in a real gpu frame capture.